A single prompt. That was all Microsoft's own security team needed to get a Semantic Kernel agent to launch calc.exe on the host machine. It did not jailbreak the model into saying something rude. It ran a process. On your server.
That report dropped May 7, and it was not the only one this month. CrewAI got hit with four CVEs that chain prompt injection into full remote code execution. Claude Code shipped a deny-rule bypass that silently switched off the security rules developers thought were protecting them. Different vendors, roughly the same window, same nasty shape underneath: the agent framework itself is now the vulnerability.
Last time I wrote about prompt injection on this site, I said the bug was the architecture, not the model. Well, here is the architecture cashing the check.
What actually broke
Three stories, because they rhyme.
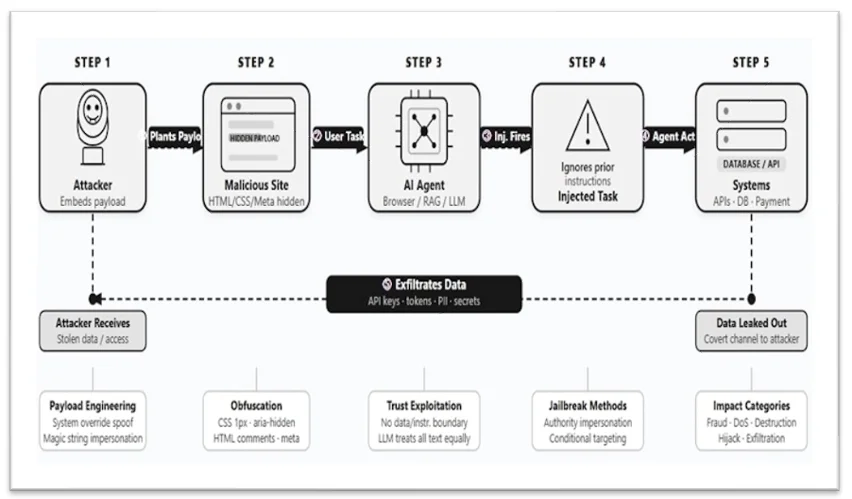
Semantic Kernel (CVE-2026-26030). Microsoft's own framework, 27,000-plus GitHub stars, the thing a lot of enterprise .NET shops reached for first. The In-Memory Vector Store with the Search Plugin built a Python lambda filter using string interpolation and ran it through eval(). On unvalidated model output. If you have ever put eval() anywhere near untrusted input, you already feel the cold sweat. A single prompt was enough to launch calc.exe on the device running the agent. Patched in Python package 1.39.4. There is a sibling, CVE-2026-25592, in the .NET SDK below 1.71.0, where DownloadFileAsync got tagged [KernelFunction] and exposed to the model with no path validation, so the agent could write a payload straight into the Windows Startup folder. Two different bugs, one root cause: a dangerous capability wired directly to model output.
CrewAI (four CVEs: 2026-2275, 2285, 2286, 2287). This one bugs me more, because the failure mode is "fall back to insecure when the safe path is unavailable." The Code Interpreter tool is supposed to run inside Docker. If Docker is not reachable, it falls back to a local SandboxPython that allows RCE (2275). It does not re-check that Docker is still running mid-execution (2287). The RAG search tool does not validate URLs, so you get SSRF into internal and cloud metadata services (2286). The JSON loader reads files with no path validation, arbitrary local file read (2285). Chain them with one prompt injection, direct or indirect, and you own the host. As of the reports there is no full patch. The maintainers are blocking modules and switching defaults to fail closed. Good. Should have been closed from day one.
Claude Code (deny-rule bypass). Anthropic's coding agent caps per-subcommand security analysis at 50 entries, down in bashPermissions.ts. Send a compound command with more than 50 subcommands joined by &&, ||, or ;, and the deny-rule enforcement just stops, falling back to a generic permission prompt. The attack is depressingly clean. You publish a repo, a developer clones it and asks Claude Code to build the project, the build command blows past 50 subcommands, deny rules are skipped, and SSH keys, AWS credentials, GitHub and npm tokens walk out the door. Fixed in v2.1.90. The kicker, and this is the part that made me put my coffee down: a correct tree-sitter parser that checks the rules regardless of command length already existed in the same repo. It was tested. It just never shipped to the regex parser that runs in public builds.
The pattern, if you only remember one thing
Every one of these is the same mistake wearing a different hat. An agent framework took a dangerous capability (run code, write files, fetch URLs, read disk) and connected it to model output with either no validation or an insecure fallback. Prompt injection is the trigger. The framework is the loaded gun it points.
This is why "we use a trusted vendor framework" is not a security control. Semantic Kernel is Microsoft. CrewAI is one of the most-starred agent projects going. Trusted is not the same thing as safe.
Darktrace's State of AI Cybersecurity 2026 put a number on the mood: 92% of security professionals are worried about the impact of AI agents. That is not a vibe. That is people who read CVE feeds for a living watching the same failure repeat across every framework on the market.
What to do this week
Pin your framework versions and read the changelogs like they owe you money. Semantic Kernel Python to 1.39.4 or higher, .NET SDK to 1.71.0 or higher. Claude Code to v2.1.90 or higher. If you run CrewAI with the Code Interpreter, treat it as exploitable today: either disable the tool or force Docker-only with no fallback, and do not wait for the full patch.
Then the bigger move, the one that actually matters. Stop giving a single agent the ability to read untrusted input and execute code in the same process. I know I keep banging this drum. The trifecta audit from the last piece applies directly here. An agent that browses the web and runs a code interpreter is a CrewAI CVE waiting for a prompt.
Log every tool call. If your agent can shell out, the shell-out log is your incident timeline, and you want it before the incident, not after.
And turn off the fallbacks. The CrewAI bug is, fundamentally, fail open instead of fail closed. Go find every place your stack drops to a less-secure mode when the secure one is unavailable, and make it fail closed instead. That is a half-day grep and it is the single highest-value thing on this list.
There is a whole separate conversation about multi-agent chains, where agent A's compromised output becomes agent B's trusted input, and honestly I do not have a clean answer for it yet. Another piece, once the research settles.
The closer
Microsoft has already promised follow-up write-ups on LangChain and other frameworks, which tells you they expect the same bugs there. They are right to. The agent-framework gold rush shipped a lot of demoware into production, and the security review is happening now, in public, one CVE at a time. The teams pinning versions and killing fallbacks this quarter will read these reports as confirmation they got the architecture right. The ones who wired calc.exe to a chatbot and called it an MVP will read them as a post-mortem about their own product.
Sources
- Microsoft Security: When prompts become shells (May 7, 2026)
- SecurityWeek: CrewAI Vulnerabilities Expose Devices to Hacking
- CERT/CC VU#221883: CrewAI SSRF, RCE and local file read
- The Register: Claude Code bypasses safety rule if given too many commands
- Cybersecurity News: Claude Code deny-rule bypass
- Darktrace: State of AI Cybersecurity 2026